Flowlogistic Case Study -
Company Overview -
Flowlogistic is a leading logistics and supply chain provider. They help businesses throughout the world manage their resources and transport them to their final destination. The company has grown rapidly, expanding their offerings to include rail, truck, aircraft, and oceanic shipping.
Company Background -
The company started as a regional trucking company, and then expanded into other logistics market. Because they have not updated their infrastructure, managing and tracking orders and shipments has become a bottleneck. To improve operations, Flowlogistic developed proprietary technology for tracking shipments in real time at the parcel level. However, they are unable to deploy it because their technology stack, based on Apache Kafka, cannot support the processing volume. In addition, Flowlogistic wants to further analyze their orders and shipments to determine how best to deploy their resources.
Solution Concept -
Flowlogistic wants to implement two concepts using the cloud:
Use their proprietary technology in a real-time inventory-tracking system that indicates the location of their loads

✑ Perform analytics on all their orders and shipment logs, which contain both structured and unstructured data, to determine how best to deploy resources, which markets to expand info. They also want to use predictive analytics to learn earlier when a shipment will be delayed.
Existing Technical Environment -
Flowlogistic architecture resides in a single data center:
✑ Databases
8 physical servers in 2 clusters
- SQL Server `" user data, inventory, static data
3 physical servers
- Cassandra `" metadata, tracking messages
10 Kafka servers `" tracking message aggregation and batch insert
✑ Application servers `" customer front end, middleware for order/customs
60 virtual machines across 20 physical servers
- Tomcat `" Java services
- Nginx `" static content
- Batch servers
✑ Storage appliances
- iSCSI for virtual machine (VM) hosts
- Fibre Channel storage area network (FC SAN) `" SQL server storage
- Network-attached storage (NAS) image storage, logs, backups
✑ 10 Apache Hadoop /Spark servers
- Core Data Lake
- Data analysis workloads
✑ 20 miscellaneous servers
- Jenkins, monitoring, bastion hosts,
Business Requirements -
✑ Build a reliable and reproducible environment with scaled panty of production.
✑ Aggregate data in a centralized Data Lake for analysis
✑ Use historical data to perform predictive analytics on future shipments
✑ Accurately track every shipment worldwide using proprietary technology
✑ Improve business agility and speed of innovation through rapid provisioning of new resources
✑ Analyze and optimize architecture for performance in the cloud
✑ Migrate fully to the cloud if all other requirements are met
Technical Requirements -
Handle both streaming and batch data

✑ Migrate existing Hadoop workloads
✑ Ensure architecture is scalable and elastic to meet the changing demands of the company.
✑ Use managed services whenever possible
✑ Encrypt data flight and at rest
✑ Connect a VPN between the production data center and cloud environment
SEO Statement -
We have grown so quickly that our inability to upgrade our infrastructure is really hampering further growth and efficiency. We are efficient at moving shipments around the world, but we are inefficient at moving data around.
We need to organize our information so we can more easily understand where our customers are and what they are shipping.
CTO Statement -
IT has never been a priority for us, so as our data has grown, we have not invested enough in our technology. I have a good staff to manage IT, but they are so busy managing our infrastructure that I cannot get them to do the things that really matter, such as organizing our data, building the analytics, and figuring out how to implement the CFO' s tracking technology.
CFO Statement -
Part of our competitive advantage is that we penalize ourselves for late shipments and deliveries. Knowing where out shipments are at all times has a direct correlation to our bottom line and profitability. Additionally, I don't want to commit capital to building out a server environment.
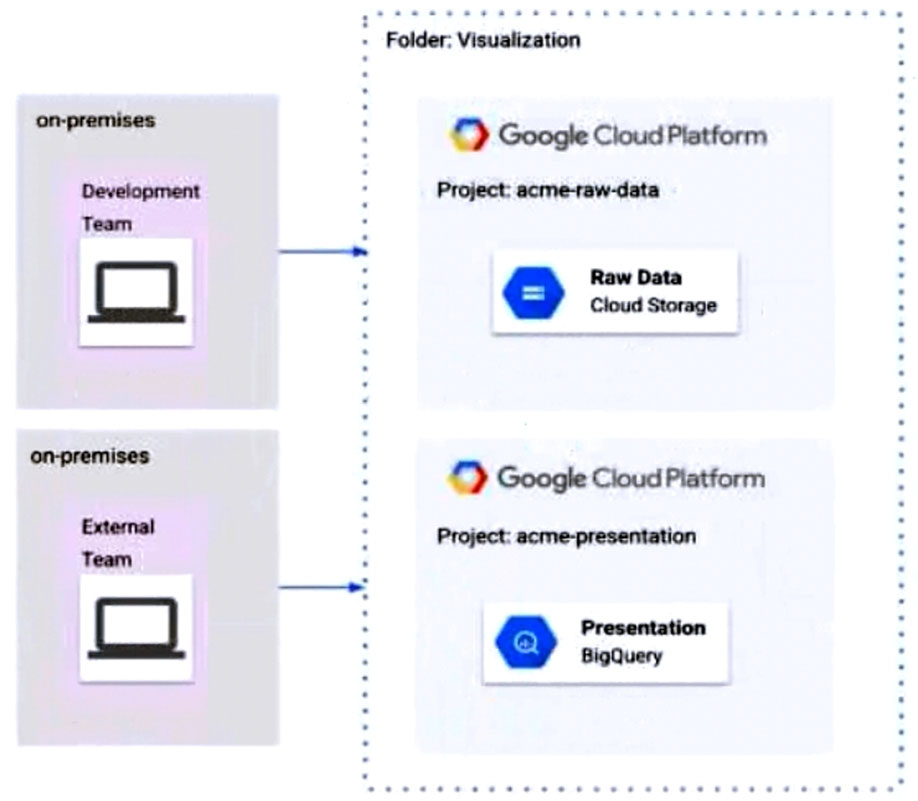
Flowlogistic's CEO wants to gain rapid insight into their customer base so his sales team can be better informed in the field. This team is not very technical, so they've purchased a visualization tool to simplify the creation of BigQuery reports. However, they've been overwhelmed by all the data in the table, and are spending a lot of money on queries trying to find the data they need. You want to solve their problem in the most cost-effective way. What should you do?
-
A.
Export the data into a Google Sheet for virtualization.
-
B.
Create an additional table with only the necessary columns.
-
C.
Create a view on the table to present to the virtualization tool.
-
D.
Create identity and access management (IAM) roles on the appropriate columns, so only they appear in a query.












Comment 1
Correct A: A . Now it is feasible to provide table level access to user by allowing user to query single table and no other table will be visible to user in same dataset.
Comment 1.1
A is not at all possible
Comment 1.1.1
It is possible for about a year now. https://cloud.google.com/bigquery/docs/table-access-controls-intro#example_use_case
Comment 1.2
The problem is that option A has a lot of work for the DevOps, meanwhile option D is easier to manage. The view is like having a shortcut to the same data, but with different permissions
Comment 1.2.1
According to Chat GPT, it is also D.
And it explains why it shouldn't be "A" as;
Granularity: While you can assign access permissions at the table level, it doesn't allow for fine-grained access control. For example, if you want to restrict access to certain columns or rows within a table based on user or group, table-level permissions would not be sufficient.
Scalability: In organizations with many tables and users, managing permissions at the table level can quickly become unwieldy. You would need to individually set permissions for each user for each table, which can be time-consuming and error-prone.
Security: Table-level permissions expose the entire table to a user or a group. If the data in the table changes over time, users might get access to data they shouldn't see. With authorized views, you have more control over what data is exposed.
Maintenance: If the structure of your data changes (for instance, if tables are added or removed, or if the schema of a table changes), you would need to manually update the permissions for each affected table.
Comment 1.3
the request says "team membership", so access depends on the team and not the user
Comment 1.4
Should still be D.
Question states - "They should only see certain tables based on their team membership"
Option A states - Assign the users/groups data viewer access at the table level for each table
With A, everyone will see every table. Hence D.
Comment 2
D should be the answer
Comment 2.1
There is only one dataset mentioned in the question here. "You have migrated all of your data into tables in a dataset"
Comment 2.2
It is updated, now A is correct
Comment 3
Why Option D is the Best Fit
In BigQuery, simply creating a view isn't enough to grant access to the underlying data. If a user has access to a view but not the source table, the query will fail. An Authorized View solves this by allowing the view itself to "authorize" access to the source data, even if the user doesn't have direct access to those tables.
Comment 4
obviously D. A is not cumbersome and difficult to manage
Comment 5
The question was created at the time when it was not possible to share data on table level (dataset was the only option). At that time D was possible only. Right now A is feasible as well.
Comment 6
Authorized views provide a centralized way to manage access. You define the data each team can see in a view and then grant access to that view. This is much easier to maintain and update than managing permissions on individual tables.
Why not D? - Option D suggests creating separate datasets for each team and using authorized views within those datasets. This adds unnecessary complexity and overhead.
You would need to manage multiple datasets.You would need to grant the authorized views access to the original dataset.
Comment 7
Table level access could be done in bigquery.
Comment 8
Recommended approach
Comment 9
Should be D.
Comment 10
https://cloud.google.com/solutions/migration/dw2bq/dw-bq-data-governance
When you create the view, it must be created in a dataset separate from the source data queried by the view. Because you can assign access controls only at the dataset level, if the view is created in the same dataset as the source data, your users would have access to both the view and the data.
https://cloud.google.com/bigquery/docs/authorized-views
This approach aligns with the Google Cloud best practices for data governance, ensuring that users can only access the data intended for them without having direct access to the source tables. Authorized views serve as a secure interface to the underlying data, and by placing these views in separate datasets per team, you can manage permissions effectively at the dataset level.
Comment 11
but the question said that all data are copied into one dataset. so it should be C
Comment 12
A is the best answer for security as stated in the documentation - https://cloud.google.com/bigquery/docs/row-level-security-intro#comparison_of_authorized_views_row-level_security_and_separate_tables
Comment 13
A is a better fit than D for this case
Comment 14
Authorized Views: Authorized views in BigQuery allow you to control access to specific rows and columns within a table. This means you can create views for each team that restrict access to only the data relevant to that team.
Single Dataset: Keeping all the authorized views and the underlying data in the same dataset simplifies management and access control. It avoids the need to create multiple datasets, making the permission management process more straightforward.
Option A (assigning data viewer access at the table level) would not provide the granularity you need, as it would allow users to see all tables in the dataset. This does not align with the requirement to restrict access based on team membership.
Comment 15
https://cloud.google.com/bigquery/docs/share-access-views#:~:text=the%20source%20data.-,Authorized%20views,-should%20be%20created
For best practice, Option D is bettern than others.
Comment 16
[A] is correct if it is for individual table
However, in practice we normally do [C] as most of the time, the view is a JOIN of a few tables or a subset of the table (some columns removed)
Comment 17
Answer A, Trick here is, if question is not asking for data level Access such as some rows or columns, don't go for authorized view in that case i would go for C. If it's Table level request only in question, then A is simple answer